NVLINK И INFINIBAND
ПРОТОКОЛЫ С УЛЬТРАНИЗКОЙ ЗАДЕРЖКОЙ
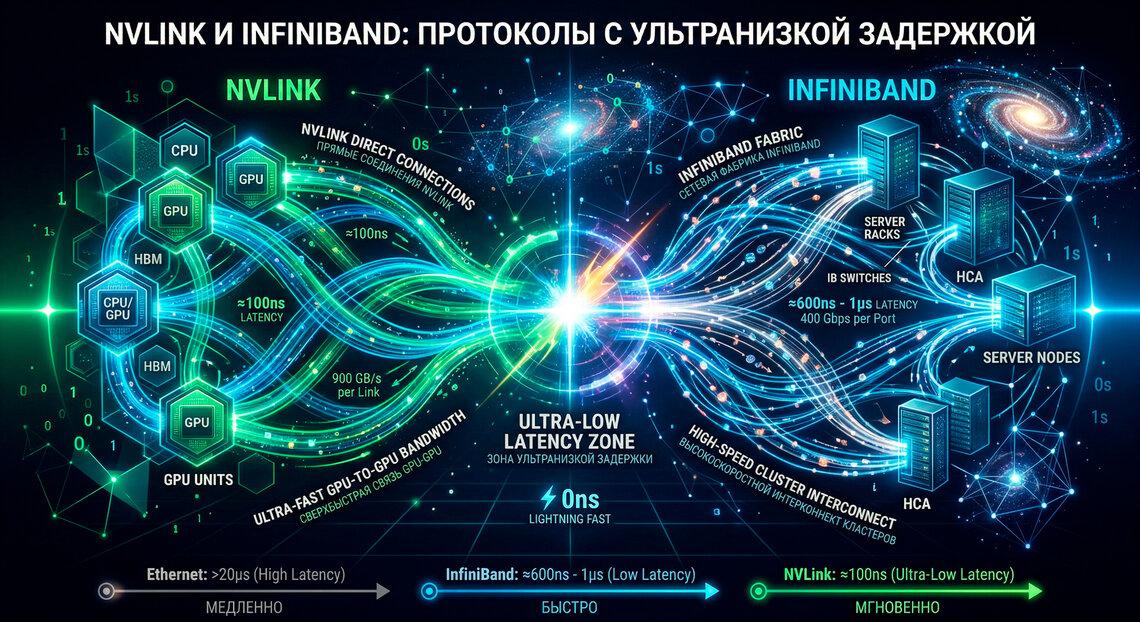
Современные вычислительные кластеры для обучения LLM (Large Language Models) и высокопроизводительных вычислений (HPC) сталкиваются с барьером «memory wall» и задержками межчипового взаимодействия. Для эффективного масштабирования требуются протоколы, обеспечивающие когерентность памяти, высокую пропускную способность и минимальный джиттер. На передовой этой войны технологий закрепились два архитектурных гиганта: проприетарный NVLink ( Scale-Up внутри домена) и открытый стандарт InfiniBand (Scale-Out межузловая сеть).
Если десятилетие назад производительность AI определялась пиковой мощностью FP32/FP16 на чипе, то сегодня главным ограничителем (bottleneck) стала скорость перемещения данных между чипами. Модели растут быстрее, чем пропускная способность памяти, делая сетевой интерконнект критической частью архитектуры.
Глубокий инженерный разбор NVLink (V5/V6)
NVLink — это не просто кабель, это проприетарная "нервная система" от NVIDIA, отточенная до блеска для одной задачи: перемещать данные между GPU так, как будто они находятся на одном кристалле. Протокол использует семантику прямого доступа к памяти, минимизируя программные накладные расходы.
Физика и логика превосходства
- - PAM4 Революция: Основа успеха — высокоскоростные SerDes с модуляцией PAM4. В новейших итерациях (архитектуры Blackwell/Rubin) скорость на одну линию взлетела до невероятных 224 Гбит/с.
- - NVSwitch — Матрица доминирования: Забудьте о кольцевых топологиях. Переход к неблокирующей матрице через чипы NVSwitch прорывает ограничения. Это позволяет объединять 72 и более GPU в единый логический домен с общей памятью. Программист видит один гигантский супер-GPU с петабайтами HBM-памяти.
- - Memory-Mapped I/O: Протокол работает на уровне транзакций памяти (аппаратный Load/Store). Никакого TCP/IP стека, никакого программного RDMA — только чистое железо, только аппаратная когерентность.
Инженерные ограничения и цена скорости
Но физику не обмануть. На таких частотах затухание в медных проводниках (DAC) становится критичным, ограничивая дистанцию соединения сантиметрами. При переходе на оптические NVLink-соединения (NVLink-over-Fiber) неизбежно увеличивается задержка из-за процессов модуляции и демодуляции сигнала.
Кроме того, невероятная плотность портов NVSwitch требует колоссальных затрат на охлаждение. При плотности мощности > 100 кВт на стойку традиционное воздушное охлаждение капитулирует, делая CAPEX на инфраструктуру жидкостного охлаждения (CDU, коллекторы) обязательным пунктом бюджета.
Анатомия InfiniBand (NDR/XDR)
В то время как NVLink царит внутри стойки, InfiniBand (IB) — это признанный стандарт для объединения тысяч узлов в единый суперкомпьютер. Его философия — перемещение транспортного уровня на аппаратный уровень для достижения минимальных задержек.
Ключевые технологии разгона кластера
- - Чистый аппаратный RDMA: Remote Direct Memory Access позволяет передавать данные напрямую из памяти одного узла в память другого, полностью минуя CPU и операционную систему обеих сторон. Процессоры заняты вычислениями, а не перекладыванием пакетов.
- - Вычисления внутри сети (SHARP): Коммутаторы InfiniBand — это не просто регулировщики. SHARP выполняет агрегацию и редукцию данных. Критические для AI операции (например, AllReduce при градиентном спуске) выполняются в логике чипа коммутатора. - SHARP экономит пропускную способность, избавляя сеть от передачи промежуточных данных до CPU.
- Адаптивная маршрутизация и Adaptive Congestion Control: Эти технологии в реальном времени направляют пакеты по менее загруженным путям, минимизируя tail latency (задержку 99-го перцентиля), которая часто тормозит весь расчет.
В гигантских кластерах ИИ (сотни/тысячи GPU) средняя задержка не имеет значения. Решает tail latency (задержка самого медленного пакета). Если один пакет застрял, весь AllReduce ждет. InfiniBand доминирует в Scale-Out именно за счет минимизации tail latency в сложных топологиях.
Сравнительный анализ параметров интерконнекта
| Параметр | NVLink (эра Blackwell) | InfiniBand (NDR1200 / XDR) |
|---|---|---|
| Назначение и Топология | Scale-Up (внутри стойки, когерентный домен) | Scale-Out (между стойками, весь кластер) |
| Характер задержки | Наносекундная (< 100 нс) | Микросекундная (0.6 – 1.2 мкс) |
| Пропускная способность (Aggregate) | До 1.8 Тбайт/с на GPU | До 800 – 1600 Гбит/с на порт |
| Стек протоколов | Memory-mapped I/O (аппаратный Load/Store) | RDMA / Verbs API / SHARP |
| Экосистема и Среда | Проприетарный, Медь (Flyover), Оптика | Открытый стандарт, Оптика |
| Энергоэффективность (pJ/bit) | В 2.5 – 3 раза лучше, чем IB | Ниже за счет сложной инкапсуляции |
На скоростях 224 Гбит/с на линию затухание в меди критично: текстолит печатных плат "съедает" сигнал через несколько дюймов. Решение: использование "flyover" кабелей внутри шасси, пускающих сигнал напрямую поверх плат. Это усложняет конструкцию, но позволяет сохранить медь на критических дистанциях.
Реальные метрики и оценка рисков
- Производительность AI в задачах All-to-All: Переход с InfiniBand на NVLink внутри домена из 72 GPU дает прирост пропускной способности в 4 – 9 раз. Для градиентного спуска это критично.
- Плотность мощности и CAPEX охлаждения: Использование NVSwitch позволяет достичь плотности 100 – 120 кВт на стойку. Это требует дорогостоящей инфраструктуры жидкостного охлаждения, увеличивая начальный CAPEX, но снижая OPEX на пересчете мощности на переданный терабайт.
Оценка рисков и несостоятельности решений
- Риск "Incast" и перегрузок в IB: При неправильной настройке адаптивной маршрутизации в больших Fat-Tree сетях возникают "горячие точки" (incast), что резко увеличивает tail latency, замедляя весь расчет.
- Экономическая несостоятельность NVLink на дистанции: Попытка растянуть NVLink Fabric за пределы одной-двух стоек требует запредельно дорогих оптических коммутаторов NVSwitch, что делает CAPEX неоправданно высоким по сравнению с более дешевым экономически масштабируемым IB.
Итоговый архитектурный вердикт
В современной борьбе за пропускную способность не существует универсального решения. Побеждает гибридная архитектура. Для систем с числом GPU до 72 единиц оптимальной средой для Scale-Up домена служит NVLink Fabric. Когда же кластер преодолевает порог в 512 GPU, единственной магистралью для неограниченного масштабирования (Backend Network) становится InfiniBand.
© Материал подготовлен специалистами в области инженерной инфраструктуры SYSMATRIX Lab | Март 2026.
Оставайтесь на связи
Подпишитесь на новостную рассылку и будьте в курсе всех интересных событий и предложений!
Никакого спама гарантированно!